Webscraping in R
Things to Look for as a Beginner
These are the three functions that are used during this presentation for webscraping. These are the only functions that are used from the "rvest" package. Everything else in this presentation is base R.
- read_html()
- html_nodes()
- html_table()
What is Web Scraping?
Web scraping is the process of automatically collecting data from web pages without visiting them using a browser. This can be useful for collecting information from a multitude of sites very quickly. Also, because the scraper searches for the location of the information within the webpage it is possible to scrape pages that change daily to get the updated information.
Scraping in R using rvest
We will focus on scraping without any manipulation of the webpages that we visit. Webpage manipulation while scraping is possible, but it can not be done exclusively in R which is why we will be ignoring it for this lesson.
What is HTML?
HTML stands for HyperText Markup Language. All HTML pages are built using the same format. A very generalized version of this is that a page should always have a header, a body, and a footnote. This isn't always the case though and is up to the developer.
The HTML Tree

Information to Gather
Let's collect some environmental data. I want to know what the weather station on the roof is reporting right now. The url for the PACCAR Weather Station is
http://micromet.paccar.wsu.edu/roof/
Install rvest
This is a package for R that should download the webpage as html for further manipulation.
1# Load the library
2if(!require(rvest)){
3 install.packages("rvest")
4 library(rvest)
5}
Download the HTML
First we need to tell R to navigate to the site and save the current html of the page.
1# Save the url as a variable
2weather.station <- read_html('http://micromet.paccar.wsu.edu/roof/')
Extract Values From Table
Next we specify the html nodes that we are interested in. In this case these are all referred to with the label "font" which allows us to specify that we want all values from the page that are labeled "font".
1# Extract the table values from the HTML
2table.values <- html_nodes(weather.station, xpath = '//font/text()')
Visualize the Table
1head(table.values, 13)
2
3## {xml_nodeset (13)}
4## [1]
5## [2] Latest time
6## [3] 2018-10-08 09:10:00
7## [4] Net Radiation
8## [5] 106.7 Wm
9## [6] Temperature
10## [7] 8 &deg C ( 46.4 &deg F )
11## [8] Humidity
12## [9] 76.8 %
13## [10] Pressure
14## [11] 923.4 mbar
15## [12] Wind speed
16## [13] 2.7 m/s (6 mph)
Save the Values as Individual Variables
We're going to save the values that we want from the previous list as individual variables
1# Time
2scraped.datetime <- as.character(table.values[3])
3# Radiation
4radiation <- as.character(table.values[5])
5# Temperature
6temperature <- as.character(table.values[7])
7# Humidity
8humidity <- as.character(table.values[9])
9# Pressure
10pressure <- as.character(table.values[11])
11# Wind Speed
12wind.speed <- as.character(table.values[13])
13# Rain
14rain <- as.character(table.values[17])
View the Variables to Check Formatting
Let's view one of our variables to see how it is formatted now.
1# Print the variable to the console
2scraped.datetime
3
4## [1] " 2018-10-08 09:10:00 "
Split the Datetime into Date and Time
1# Use strsplit to separate into a list
2datetime <- strsplit(scraped.datetime, " ")
3# View the list after the split
4datetime
5
6## [[1]]
7## [1] "" "" "2018-10-08" "09:10:00"
8
9# Select and save the scraped date
10scraped.date <- datetime[[1]][3]
11# Select and save the scraped time
12scraped.time <- datetime[[1]][4]
13# Print the time
14scraped.time
15
16## [1] "09:10:00"
Create a Function to Scrape Radiation
1# This is our radiation scraping function
2scrape.raditation <- function(){
3 # Download the html
4 weather.station <- read_html('http://micromet.paccar.wsu.edu/roof/')
5 # Extract the table values
6 table.values <- html_nodes(weather.station, xpath = '//font/text()')
7 # Save the radiation value
8 radiation <- as.character(table.values[5])
9 # Split the string
10 radiation.temp <- strsplit(radiation, " ")
11 # Return only the numerical value
12 return(radiation.temp[[1]][3])
13}
Let's Try Our Radiation Function
1# Execute the function
2scrape.raditation()
3
4## [1] "106.7"
Web Scraping Tables
1# Function to scrape votesmart.org
2voting.record <- function(candidate, pages){
3 # Create an empty data frame
4 df <- NULL
5 # Collect all data from the table on each page
6 for (page in 1:pages){
7 # Paste the URLs together
8 candidate.page <- paste(candidate, "/?p=", page, sep = "")
9 # Download the html for the page
10 candidate.url <- read_html(candidate.page)
11 # Save the record as a table
12 candidate.record <- as.data.frame(html_table(candidate.url)[2])
13 # Row bind the current table to the rest
14 df <- rbind(df, candidate.record)
15 }
16 return(df)
17}
Run the Function
1# Website for Cathy McMorris Rogers' voting rcord
2cathy <- "https://votesmart.org/candidate/key-votes/3217/cathy-mcmorris-rodgers"
3# Website for Lisa Brown's voting record
4lisa <- "https://votesmart.org/candidate/key-votes/3180/lisa-brown"
5
6# Scrape Cathy's voting record
7cathy.df <- voting.record(cathy, 21)
8# Scrape Lisa's voting record
9lisa.df <- voting.record(lisa, 2)
View Some Lines from Cathy's Record
1## Date Bill.No.
2## 1 Sept. 28, 2018 HR 6760
3## 2 Sept. 26, 2018 HR 6157
4## 3 Sept. 13, 2018 HR 1911
5## Bill.Title
6## 1 Protecting Family and Small Business Tax Cuts Act of 2018
7## 2 Department of Defense and Labor, Health and Human Services, and Education Appropriations Act, 2019
8## 3 Special Envoy to Monitor and Combat Anti-Semitism Act of 2018
9## Outcome Vote
10## 1 Bill Passed - House(220 - 191) Yea
11## 2 House(361 - 61) Yea
12## 3 House(393 - 2) Yea
View Some Lines from Lisa's Record
1## Date Bill.No.
2## 1 April 11, 2012 HB 2565
3## 2 April 11, 2012 SB 5940
4## 3 April 10, 2012 SB 6378
5## Bill.Title
6## 1 Roll-Your-Own Cigarette Tax Requirements
7## 2 Amends Public School Employees Retirement Benefits
8## 3 Amends State Employee Pension System
9## Outcome Vote
10## 1 Bill Passed - Senate(27 - 19) Yea
11## 2 Bill Passed - Senate(25 - 20) Nay
12## 3 Bill Passed - Senate(27 - 22) Nay
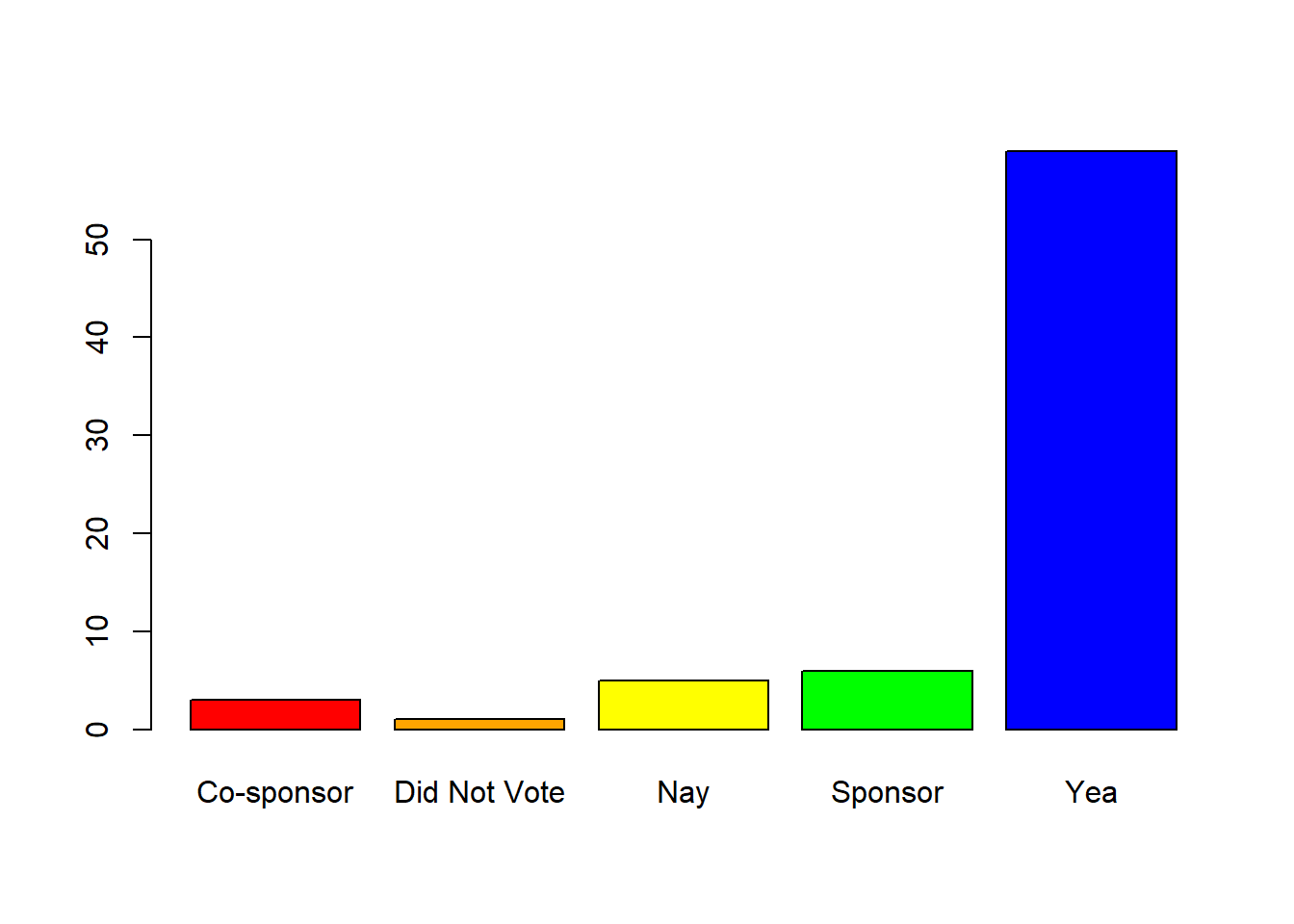
View Cathy's Voting Distribution

View Lisa's Voting Distribution
There is so much more that can be done with webscraping, but this code should be enough to get you up and running using rvest to scrape.